Smart Word Wrap
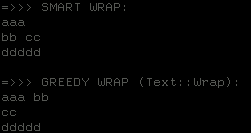
Recursion? Oh, we all love it! This post will try to illustrate how useful the recursion is and how complicated it can get sometimes. We, programmers, use recursion frequently to create small and elegant programs which can do complicated things. Just think about how would you split the following sequence "aaa bb cc ddddd" into individual rows with a maximum width of 6 characters per row. Well, one solution is to go from the left side of the string and just take words, and when the width limit is reached, append a newline. This is called the 'greedy word wrap algorithm'. It is very fast, indeed, but the output is not always pretty. Here enters another algorithm into play. We call it the 'smart word wrap algorithm'. Don't be fooled by the name. It's not smart at all! It can be, but not this one. For now it just tries in its head all the possible combinations, does some math and returns the prettiest result possible. It is much slower than the